GROUP BY timeBucket. Let’s consider a granularity of 1 day. What happens if there is no data on a Sunday? There will be no line for this Sunday. There is a great chance this will make things break later. After all, you expect your detection pipeline to know when there is no data. This case can seem non-likely to happen, but as soon as you filter on specific dimensions, the probability of this happening skyrockets.
To manage missing data, use a TimeIndexFiller node. A usual pipeline will look like this:
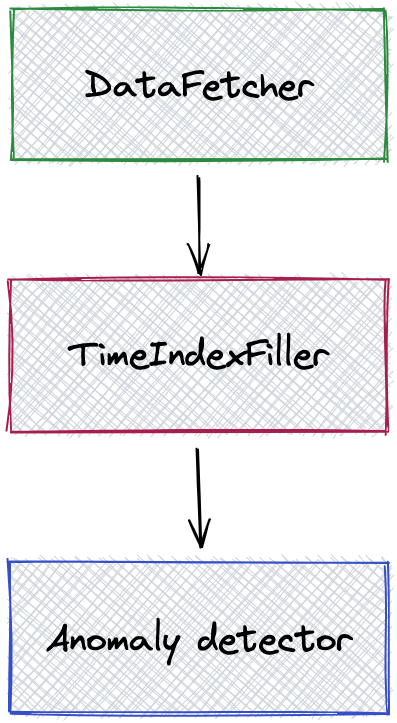
Configuration and behavior
TheTimeIndexFiller takes an input and returns it with the time index filled.
DataFetcher uses the ThirdEye macros __timeGroup(...) and __timeFilter(...), metadata about the granularity and the time predicate is directly given to the TimeIndexFiller.
Manual configuration
If the input does not use macros, theTimeIndexFiller requires the following parameters:
component.monitoringGranularity: the granularity in ISO 8601 format. Eg:P1D.component.metric: the name of the metric column.component.timestamp: the name of the time column.component.minTimeInference: the strategy to infer the minimum time.component.maxTimeInference: the strategy to infer the maximum time.component.lookback: Used when time inference uses a lookback time. In ISO 8601 format.
FROM_DATA: the minimum (resp maximum) time is the minimum (resp maximum) time observed in the input. Does not work well if data is missing at the beginning or at the end.FROM_DETECTION_TIME: the minimum (resp maximum) time is the the minimum (resp maximum) of the analysis timeframeFROM_DETECTION_TIME_WITH_LOOKBACK: same as the previous one, with an offset applied of valuecomponent.lookback.
(^1) For classic SQL databases. Timeseries-focused database often introduce group-by-time-bucket capabilities, with empty buckets materialized. Still these bucketings require a range, or use the first and last value as range, which is not correct in our case.