Frequently asked questions
Questions and clarifications about this feature:What is different between this and the Tiered Storage in open-source Apache Pinot?
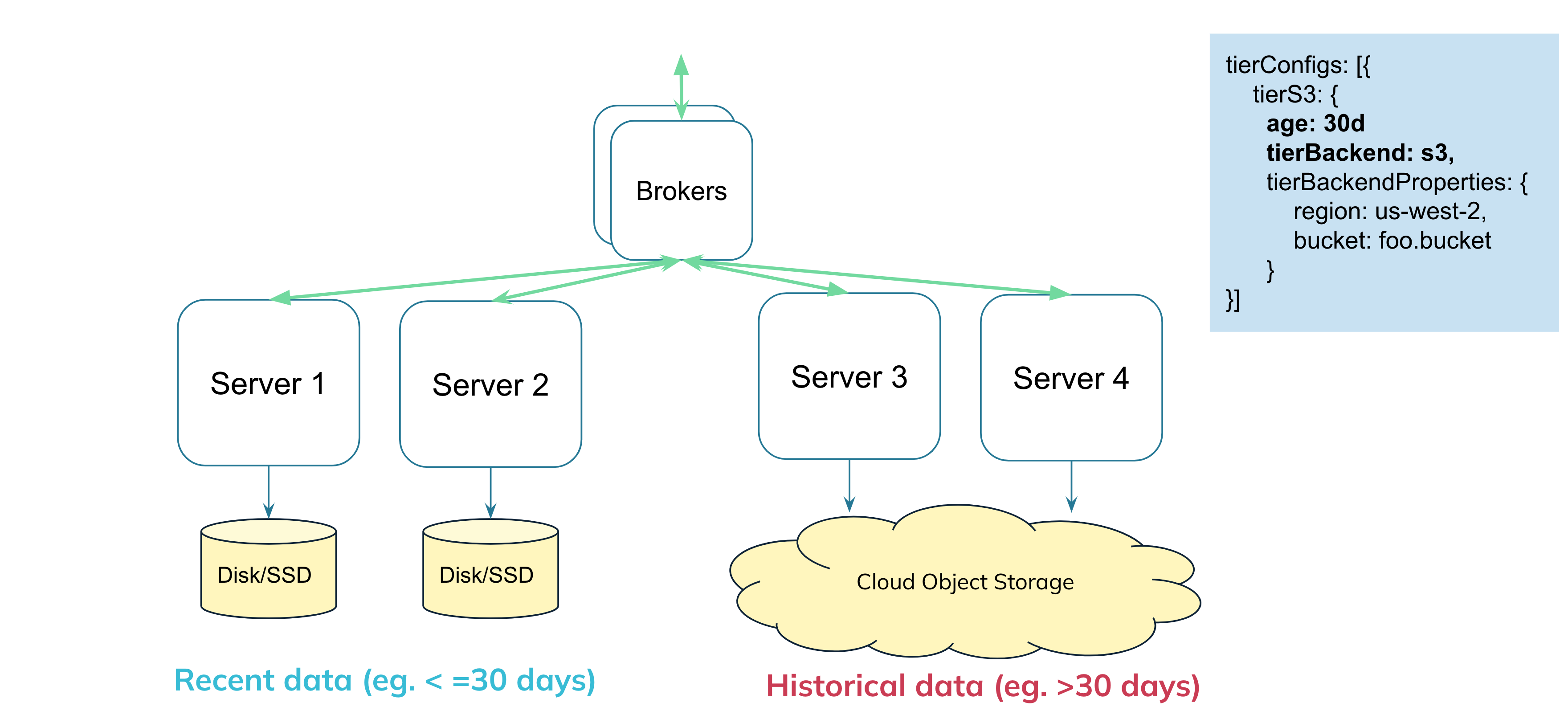
In Apache Pinot open-source, we have limited support for tiered storage (read more in the doc: Moving data from one tenant to another based on segment age). It simply lets you use multiple tenants for the same table, where each tenant can be configured to have servers of different specs (e.g. use SSD nodes for tenant 1 and lower performant cheaper HDDs as tenant 2). But the tiering stops there. We can separate the compute nodes using tenants, but are still using local storage, making us tightly coupled in terms of storage and compute.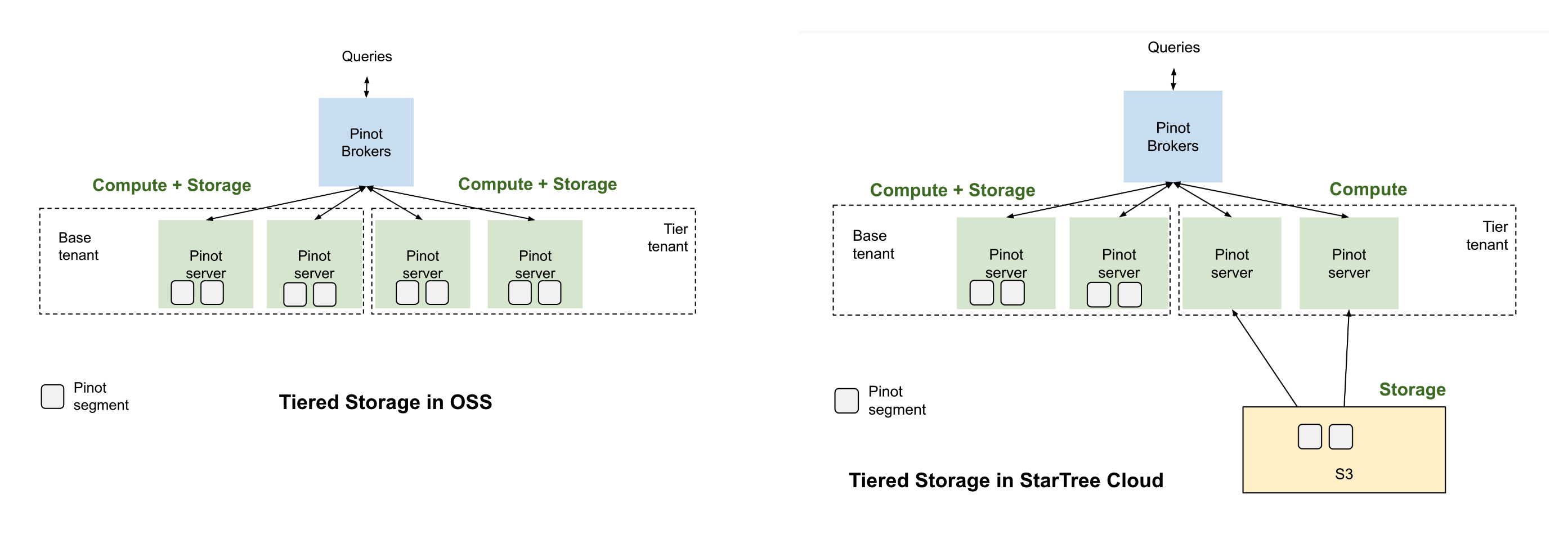
Doesn’t Pinot already have deep store? I have set up Pinot with S3/GCS as my segment store, isn’t that the same?
Many of you might be familiar with the architecture of Pinot or similar systems, and might know that these systems, along with their tightly coupled storage component, additionally also have a cloud object store like S3, GCS, ABS in their architecture. However, this segment store or deep store, is only used for permanent backups, disaster recovery, and it is not involved in the query path. With the tiered storage feature, for Apache Pinot we are now able to use the cheap cloud storage directly in the query, and replace the disk/SSDs.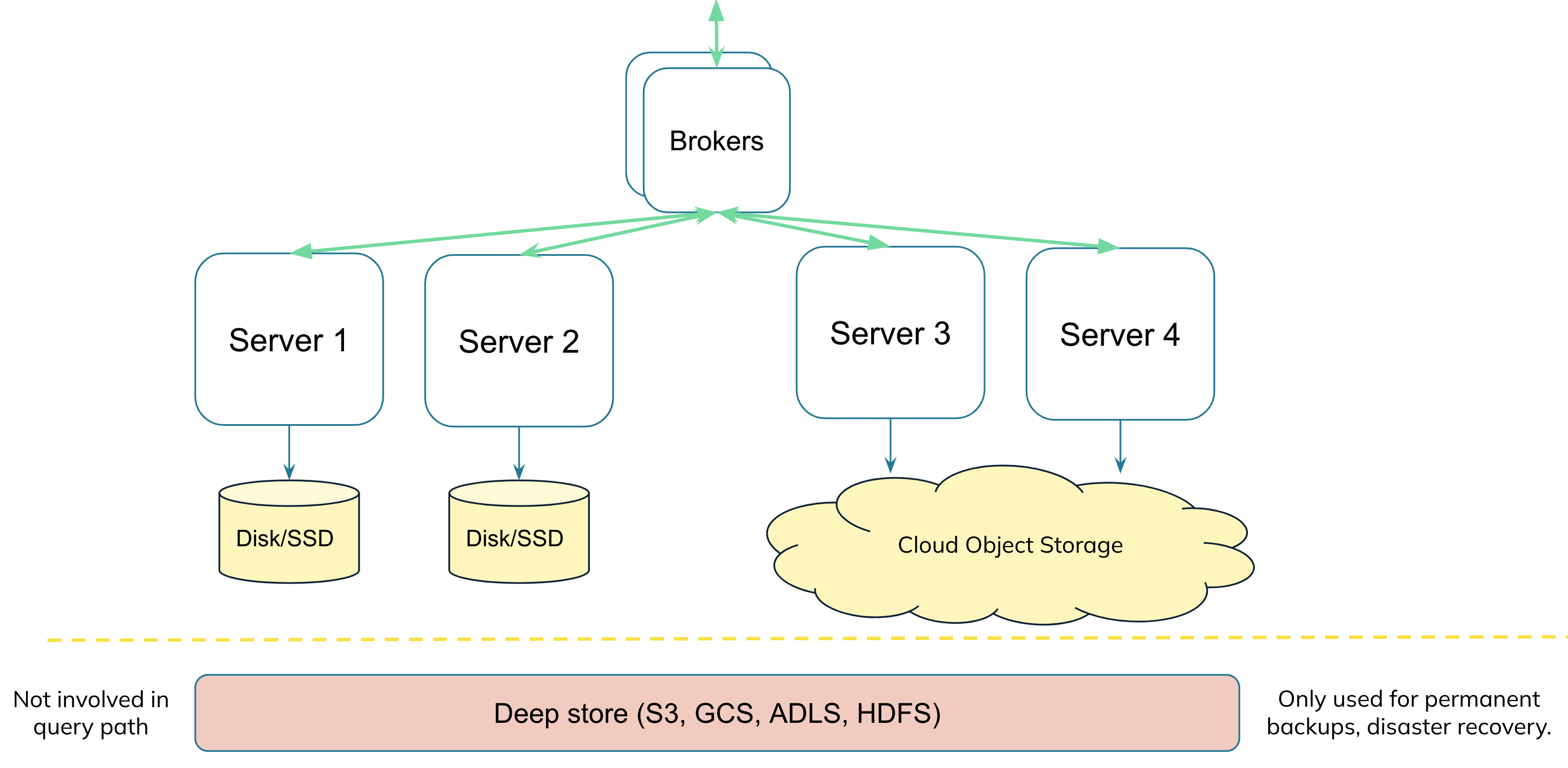
Why can’t we use the copy already in deep-store?
The segment in deep store is compressed, and typically will not have all indexes, especially if you’ve added indexes or derived columns to the segment later on. We use a separate location and copy for the tiered storage query execution, so we can keep it uncompressed and exactly in sync with what would have been on the server. Think of this S3 bucket as an exact replacement for the storage that would’ve been on the servers locally, with one major difference that we’ll keep only 1 copy in S3 vs replication number of copies locally.Is this implemented like lazy loading?
One common way that other systems in data infra solve tiering, is by using lazy loading. In lazy loading, think of your shards/segments being stored in S3, and when your query needs a segment which is on S3, it will be downloaded entirely. This means that the first access will be very slow, and your second access would find the segment locally. However, in typical OLAP workloads,- more often than not, your next query will need completely different set of segments (think arbitrary slide n dice, point lookups on various dimensions)
- or you will need more data for a single query than your local storage can keep
- Predictable p99 query latency is crucial