Usage
The off-heap upsert is enabled by default in new StarTree releases, and both FULL and PARTIAL upserts are supported. We have used RocksDB to implement the off-heap upsert. Different storage systems can be supported if needed. When using the off-heap upsert, the server creates one RocksDB store to be shared by all the upsert tables for better efficiency.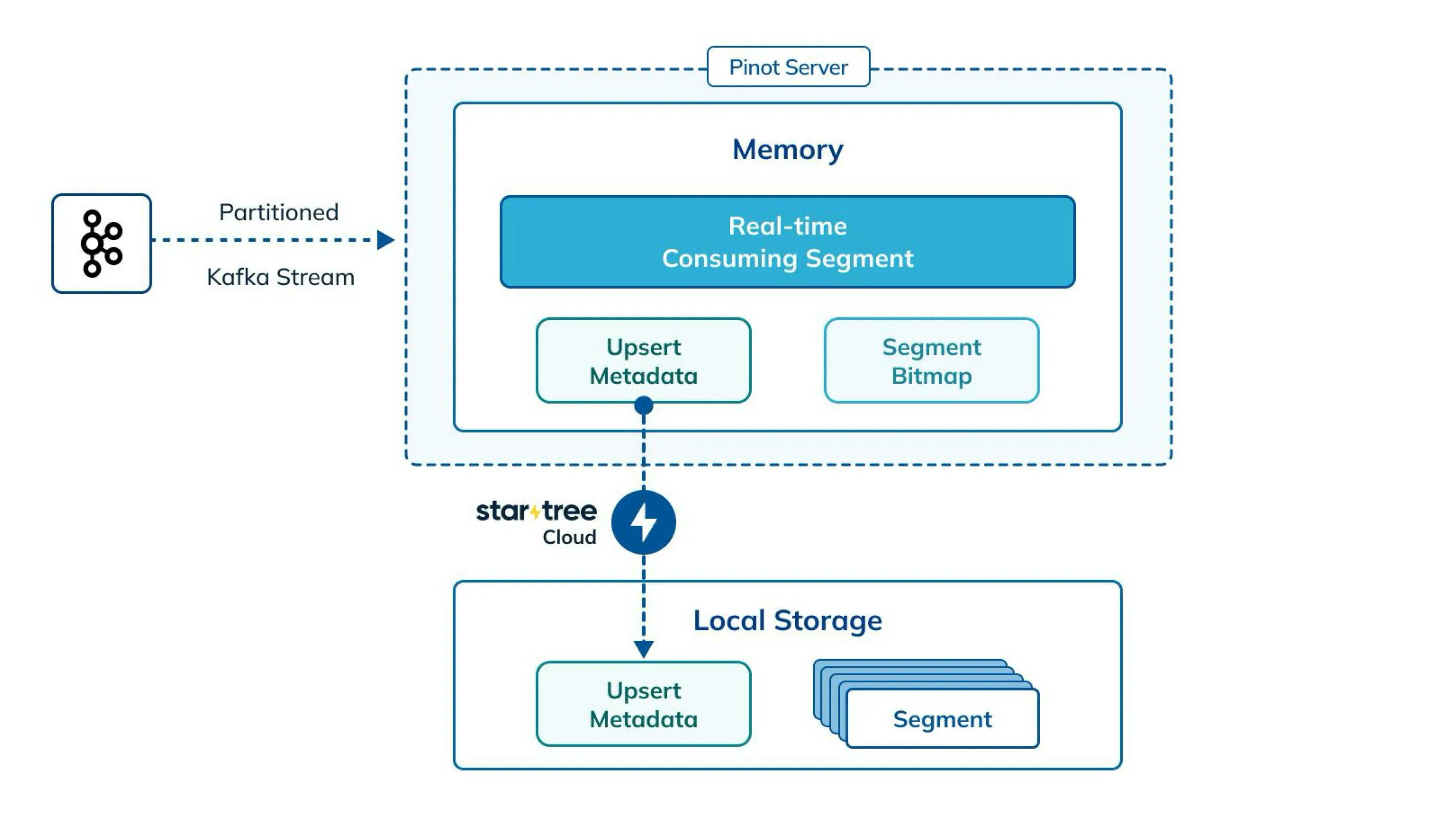
ColumnFamily in the shared RocksDB store. To customize the table’s ColumnFamily add the following RocksDB configs in the metadataManagerConfigs section. The config names are kept consistent with those available for RocksDB
Enable async removal of upsert metadata
This is enabled by default in new StarTree releases, so you can skip this section unless there is a need to customize its behavior. When a table has a lot of primary keys, its upsert metadata in RocksDB can be huge. Cleaning them up can take a long time. As this cleanup is done on the HelixTaskExecutor threads by default, those threads may be occupied for a long time, blocking the Helix state transitions from the other tables, which can potentially block the real-time data ingestion. So this async removal feature was added to move cleanup of upsert metadata to another thread pool, releasing the HelixTaskExecutor threads as soon as possible. This feature can be enabled in themetadataManagerConfigs section and customized with the configs listed below.
Use UpsertSnapshotCreation minion task
The open source implementation of the preloading feature uses the validDocIds snapshots kept on server local disk to identify valid docs and write their upsert metadata into the RocksDB store. As preloading is write-only, it can finish pretty fast in most cases. But for very large upsert tables, like those with hundreds of millions or billions of primary keys per server, this can still take a long time to finish. Besides, there are cases when servers may lose their local disks and have to download raw segments from the deep store. The raw segments don’t have validDocIds snapshots, so servers have to load them with cpu intensive read/check/write operations. To handle those issues, we have built a minion task calledUpsertSnapshotCreationTask to prebuild the upsert metadata for table partitions on the minion workers and upload the metadata to the deep store. The servers can simply download and import the prebuilt metadata into RocksDB when loading upsert tables. The prebuilt upsert metadata contains certain upsert configs and segment information for consistency check before importing to ensure data correctness.
The minion task runs periodically to keep updating the prebuilt upsert metadata incrementally.
To enable the minion task, add the following task configs. Please make sure enableSnapshot
and enablePreload are set to true in the tableConfig for this minion task to execute.
More about how to operate the minion tasks can be found in the Pinot docs.
segmentPartitionConfig field and defines a single partition column, then the UpsertSnapshotCreation task will read the number of partitions as set in the numPartitions field below.
segmentPartitionConfig field or it has two or more partition columns specified there, you must explicitly tell the UpsertSnapshotCreation task how many partitions are in the table by using the num_partition_overwrite field in the upsertConfig section like below.
Metadata TTL and deletedKeys TTL
The TTL configs as mentioned in the Pinot docs can be used for off-heap upsert too. The upsert metadata is cleaned up by the async removal feature as said above, to not block the start of new consuming segments. Besides, the UpsertSnapshotCreation minion task is also extended to support TTL configs, so that the stale upsert metadata is not included in the upsert snapshots.Enable off-heap upsert for an existing table
The off-heap upsert is enabled by default in new StarTree releases. But if you do have tables still using the on-heap upsert, then you may need to adjust the upsert configs accordingly and restart the servers to transfer the existing upsert metadata to the new backend.Segment Operation Throttling
When segments are added to a server, it undergoes various operations to come online and be ready for query processing. One of these expensive operations is related to updating the RocksDB state for upsert tables if snapshots are not available. Throttling has been added to limit the number of segments that can undergo this operation to limit the resource utilization usage during this operation. The following configs have been added to control the throttle threshold:- Before serving queries throttle threshold (default 25% of number of CPU cores):
pinot.server.max.segment.rocksdb.parallelism.before.serving.queries - After serving queries throttle threshold (default 25% of number of CPU cores):
pinot.server.max.segment.rocksdb.parallelism
Ingestion Pause on too many Primary Keys per Server
When the number of primary keys per server gets too large, this can result in various issues:- RocksDB latency increase on query and ingestion path
- Server restarts and rebalance scenarios can become slow even when snapshots exist
- The primary key count threshold (defaults to 3 billion):
controller.primary.key.count.threshold - The primary key count check timeout (defaults to 30 seconds):
controller.primary.key.count.check.timeoutMs
- Flag to enable / disable the resource utilization check:
controller.enable.resource.utilization.check - Resource utilization check frequency:
controller.resource.utilization.checker.frequency - Initial delay to start the resource utilization check:
controller.resource.utilization.checker.initial.delay