| Pinot Version | 0.9.0 |
|---|---|
| Code | startreedata/pinot-recipes/lookup-joins |
What are lookup joins?
Pinot was designed with querying single tables in mind, but sometimes we’ll have queries where we want to bring in data from other tables. Large-scale joins of Pinot tables can be done using the Presto Pinot connector. In this guide we’ll focus on joins based on lookup tables that are small in size. For example, to enrich the final result with the customer name, you can join an orders table with a customers table, which can be used as a lookup table. Joining a fact table with a small lookup table is made possible by Pinot’s Lookup UDF function. The Lookup UDF supports decoration join functionality by getting additional dimensional data via the primary key from a dimension table.Use Case
To understand how lookup joins work, let’s take a simple example. Assume we have a fact table of orders and a dimension table of customers with the following schemas.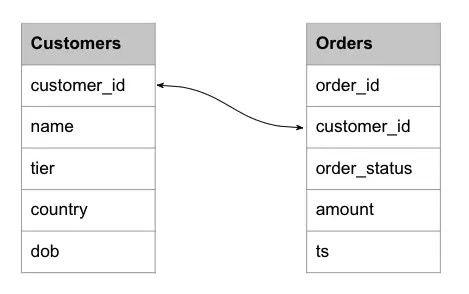
- Find all the orders placed by Gold customers.
- Find the total number of orders by customer’s tier.
- Find the top five countries by sales.
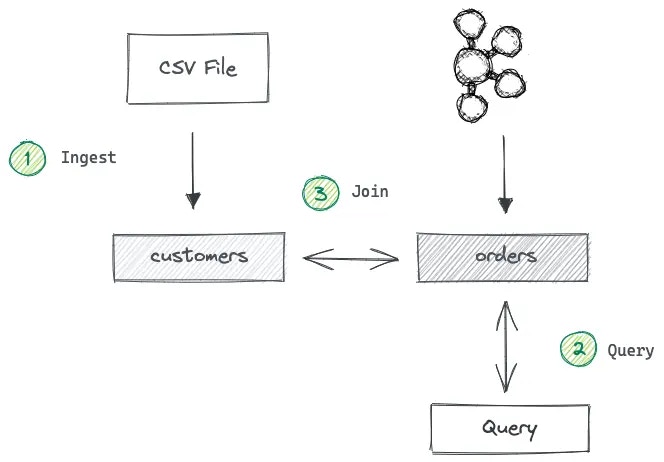
Solution Architecture
The solution is based on two Pinot tables.- Orders table – This table captures every fact about sales orders and qualifies as a fact table. We can implement this as a real-time table as new orders constantly arrive. Data ingestion takes place from a Kafka topic called the orders.
- Customers table – This captures customer dimensions and has a primary key of customer_id.
We can model this as a dimension table of OFFLINE type.
Since customer information is not frequently updated as orders, a daily batch job can be used to populate this table.
Prerequisites
To follow the code examples in this guide, you must install Docker locally and download recipes.Navigate to recipe
- If you haven’t already, download recipes.
- In terminal, go to the recipe by running the following command:
Launch Pinot Cluster
You can spin up a Pinot Cluster by running the following command:Create orders Kafka topic
Execute the following command from the project’s root directory to create a new topic called orders to represent the incoming stream of orders.Define orders table and ingest order records
Let’s first define a schema and table for the orders table. You can find the schema definition in the orders_schema.json file and table definition in the orders_table.json file. They are both located in the /config directory. In terms of configurations, they look similar to any other real-time table, so we won’t go through them here. Go ahead and execute the following command from the project’s root directory.pinot-admin.sh to create the schema and a table for orders.
Define the customers table and ingest customer records
Let’s create the customers dimension table next. You can also find the schema and table definitions inside the /config directory. You’ll notice that thecustomer_id field has been marked as a primary key in the customers_schema.json file.
Ingest sample records
Now that we have the tables created inside Pinot. Before writing any join queries, let’s ingest some sample records into both tables.Produce sample orders to Kafka
You can find two sample data files inside the /data directory. The orders.json file contains thousand of JSON formatted orders. A sample would look like this: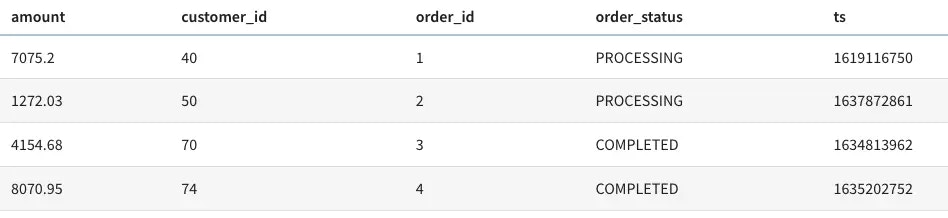
Ingest the customers CSV file
In the same /data directory, you can find the customers.csv file containing several customer records. Execute the following command to ingest them into the customers table.Write the lookup join queries
Now that we have got both tables created and populated with data. What remains is to write SQL queries that answer the questions stated above. The signature of the lookup UDF function looks similar to this: lookUp(‘dimTableName’, ‘dimColToLookUp’, ‘dimJoinKey1’, factJoinKeyVal1, ‘dimJoinKey2’, factJoinKeyVal2 … ) Where:- dimTableName - Name of the dimension table to perform the lookup on.
- dimColToLookUp - The column name of the dimension table to be retrieved to decorate our result.
- dimJoinKey - The column name on which we want to perform the lookup, i.e., the join column name for the dimension table.
- factJoinKeyVal - The value of the dimension table join column will retrieve the dimColToLookUp for the scope and invocation.
Find all the orders placed by Gold customers
What are the orders placed by Gold customers? To answer this problem, we need to write a SQL query that performs a lookup join between orders and customers table, based on customer_id. The joined result can be further filtered down on the ‘tier’ field.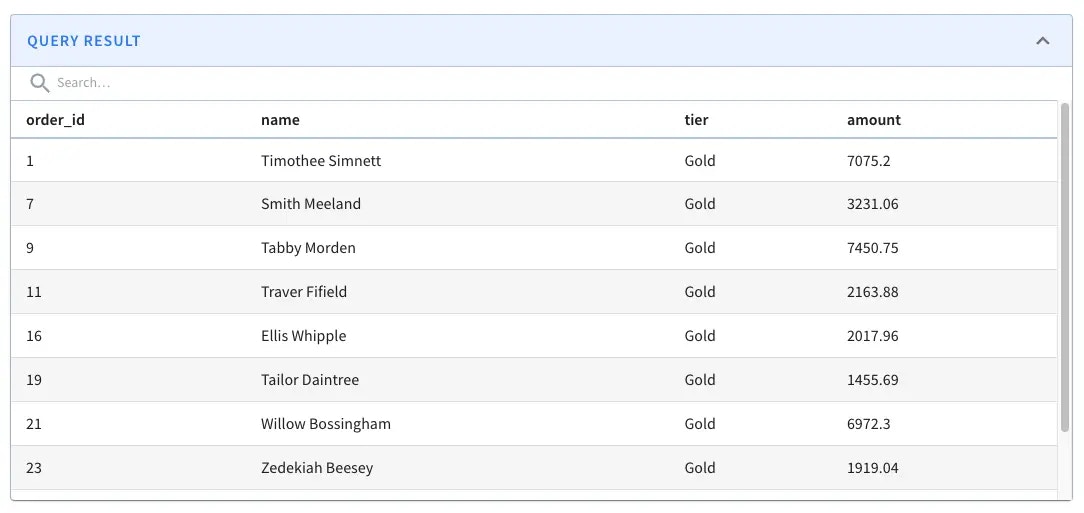
Find the total number of orders by customer’s tier
Which customer tier has made the most sales? The query looks similar to the above, but we need to aggregate the orders.amount by customers.tier.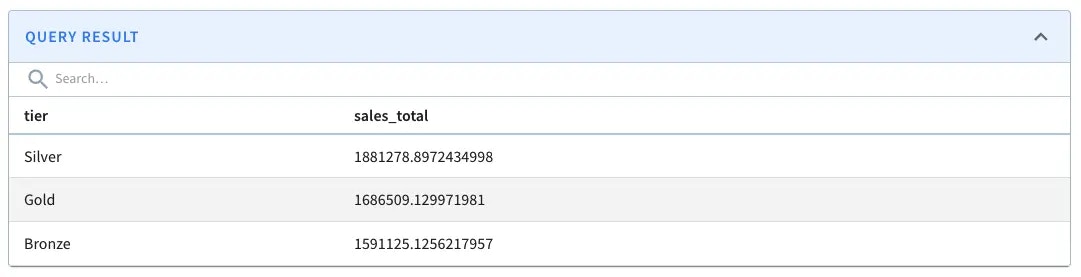
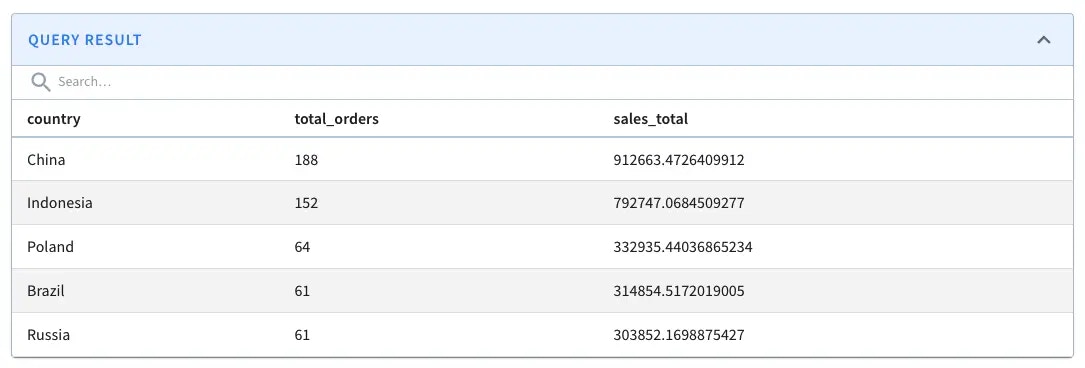
Find the top 5 countries by sales
Who are the top five countries that have contributed to the most sales? The query will be the same as the above, but we will use the customers.country field to enrich the results further.