Introduction
Imagine having the robust storage capabilities of DynamoDB combined with the lightning-fast analytics of Apache Pinot.What You’ll Need
- AWS account (with DynamoDB and Kinesis access)
- Apache Pinot cluster
- Your favorite code editor
Setting Up the Replication Pipeline
Step 1: Create a DynamoDB Table
Let’s start by creating our source of truth - a DynamoDB table.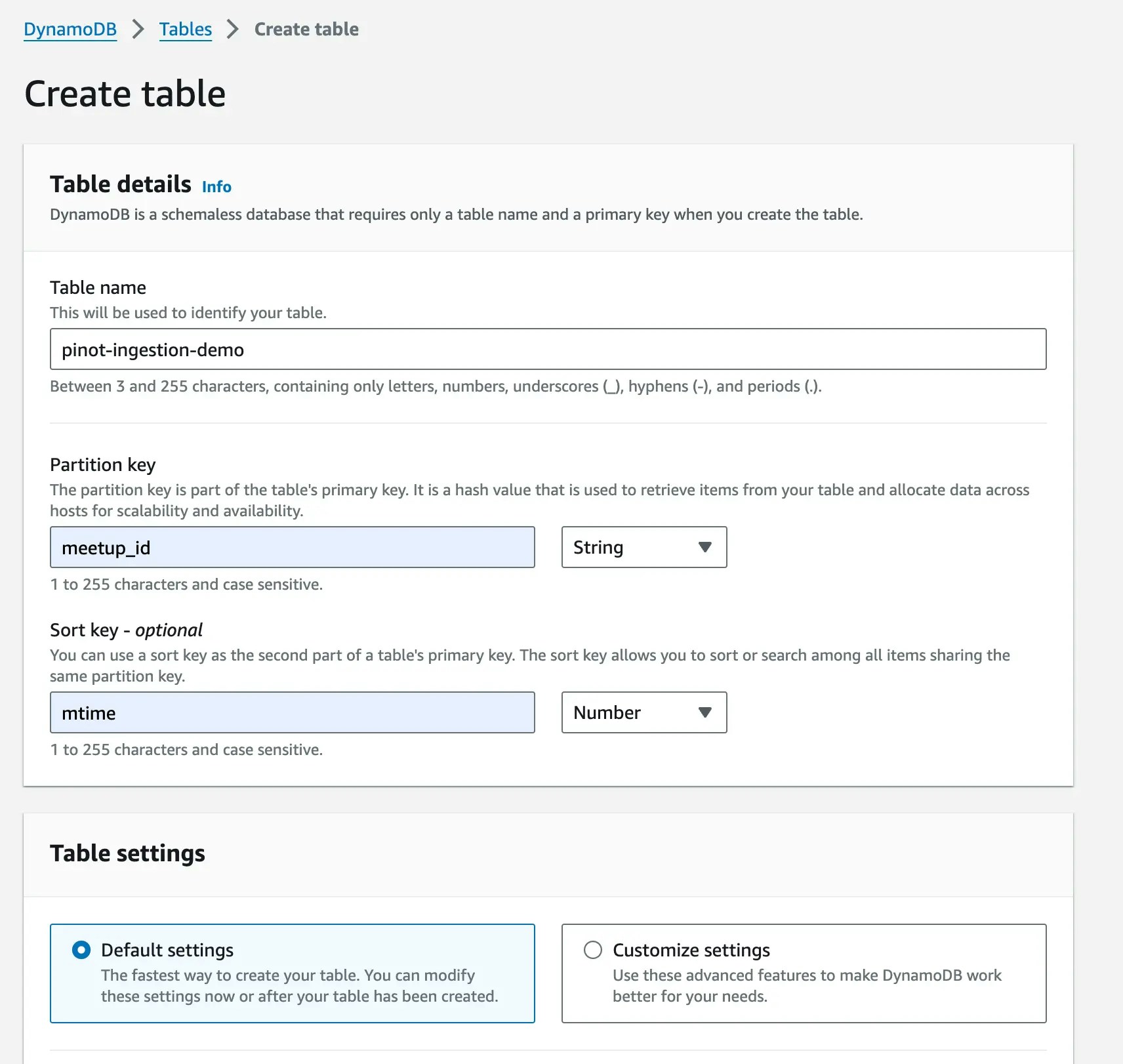
Step 2: Create a Kinesis Data Stream
Time to create a highway for our data - Kinesis stream where dynamo will push its CDC.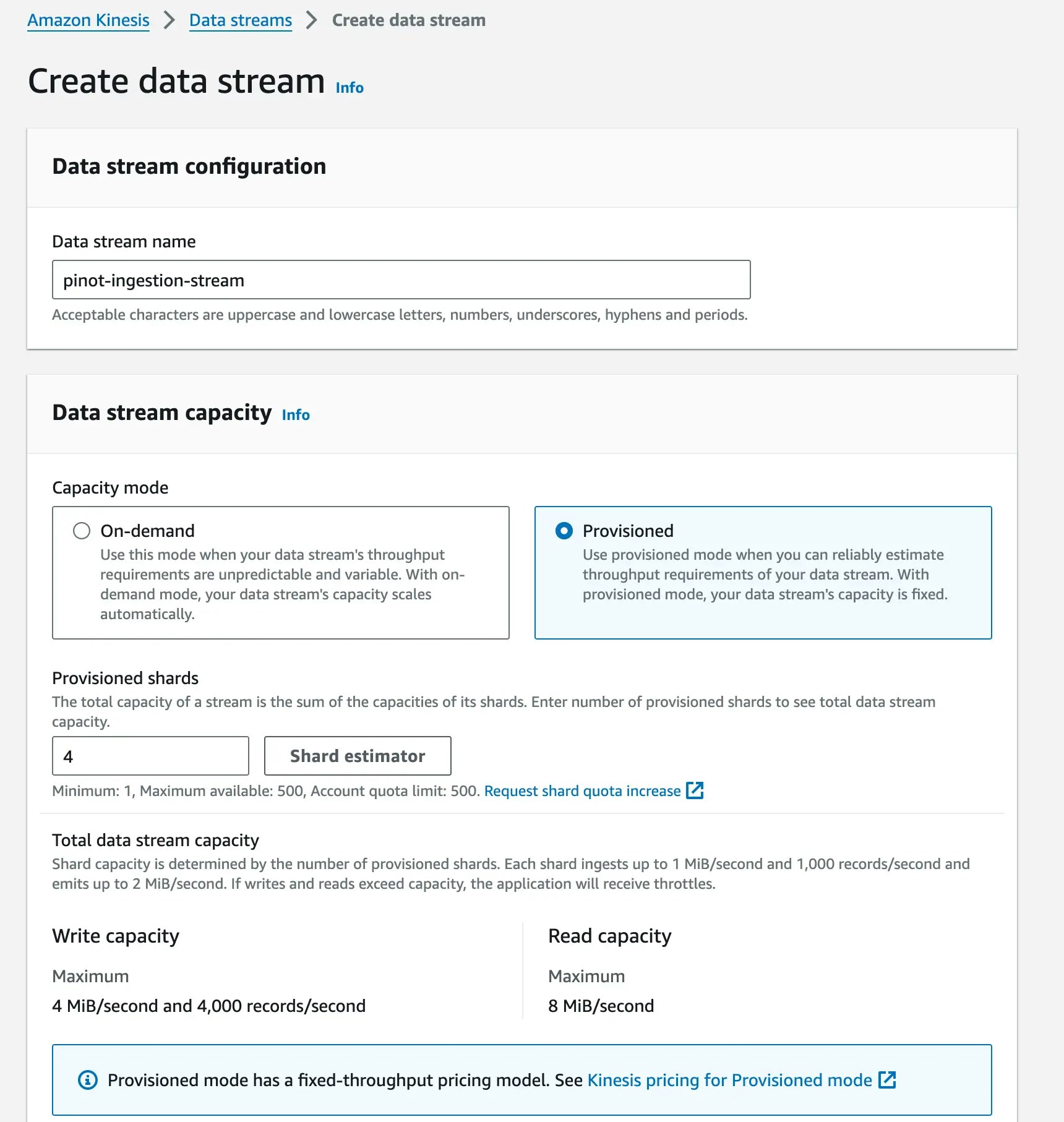
Step 3: Enable DynamoDB-Kinesis stream
Now, let’s turn on the data faucet by connecting dynamodb to kinesis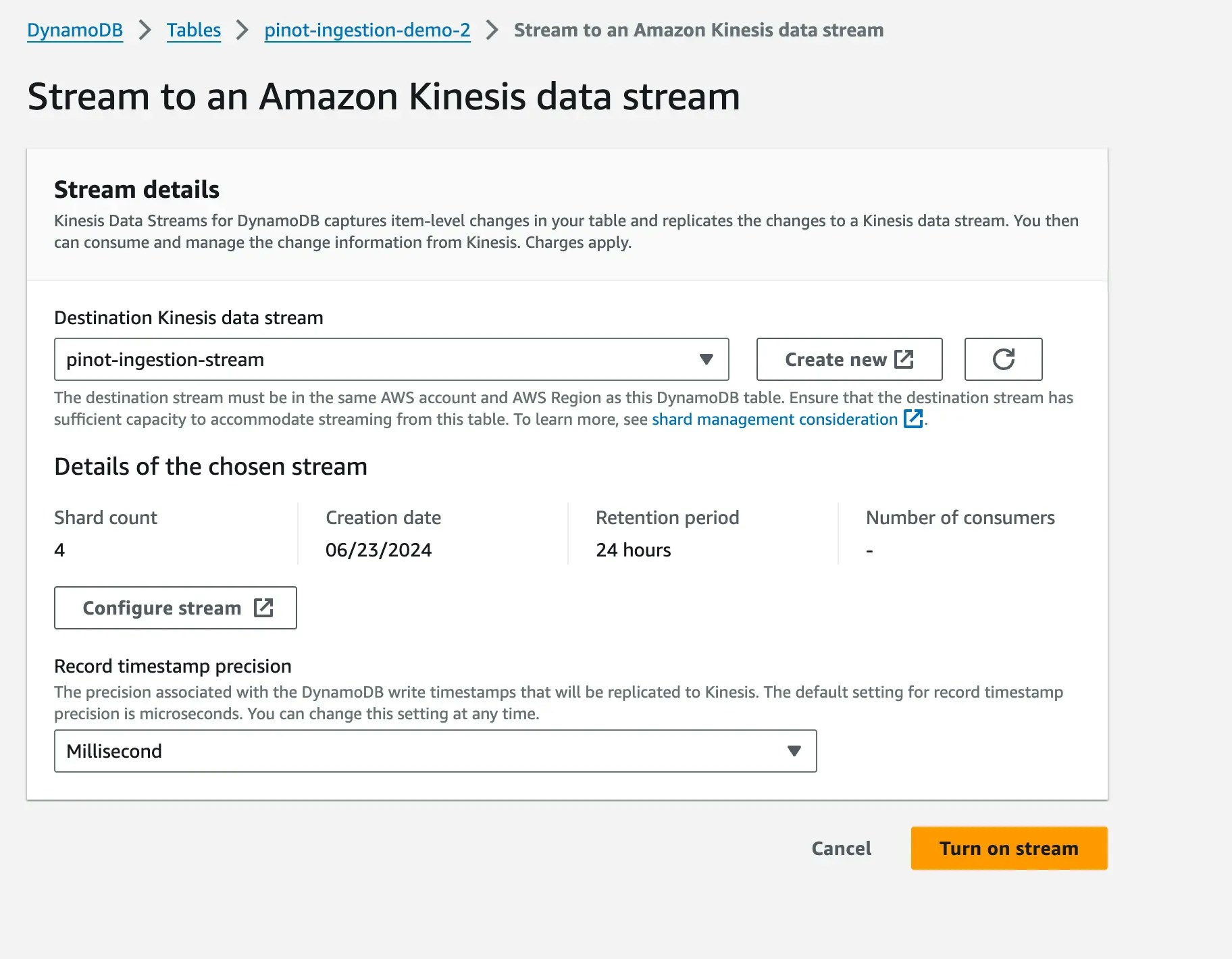
Step 4: Create Pinot Schema
Let’s tell Pinot what our data looks like:Step 5: Create Pinot Table Configuration
Now, let’s set the table for our data feast!Why do we have so many configurations?
Let’s try to understand which of these configs are necessary. When you enable CDC on dynamoDB table, it starts sending the data in the following formatDecoder Configuration
To help pinot understand the dynamodb data format, we need to add decoder configs to our tabledecoder.class.name specifies our primary decoder.
The timeColumnName specifies the column that should be filled with the ApproximateCreationDateTime from dynamodb json record.
the deleteColumnName specifies the column that should be set to true in case we receive a REMOVE record from dynamodb
Finally, the envelope.decoder.class.name simply specifies the vanilla decoder that should be used to parse the message. Since them dynamodb messages come in json format, we specify the JSONMessageDecoder here
Upserts Configuration
To handle updates properly, you need to enable upserts in Pinot. This is done in theupsertConfig section of the table configuration:
mode: Set to “PARTIAL” for partial updates.deleteRecordColumn: Specifies the column that indicates if a record should be deleted.comparisonColumns: UsesApproximateCreationDateTimeto determine the order of changes.
Derived Column for Deletions
A new derived columnis_delete is created in the schema to signify whether a key needs to be removed from the upsert metadata:
eventName in the DynamoDB stream event is “REMOVE”.
Handling Different Event Types
The configuration handles different event types as follows:- INSERT: New records are added to Pinot.
- MODIFY: Existing records are updated using the upsert configuration.
- REMOVE: Records are marked for deletion using the
is_deletecolumn.
ApproximateCreationDateTime Usage
TheApproximateCreationDateTime from the DynamoDB payload is used in the comparisonColumns of the upsert configuration. This ensures that changes are applied in the correct order, as it represents the sequence of events in DynamoDB.
Step 6: Create Pinot Table
Let’s bring our table to life!Insert, Update, Delete
Insert
Let’s add some data to our DynamoDB table: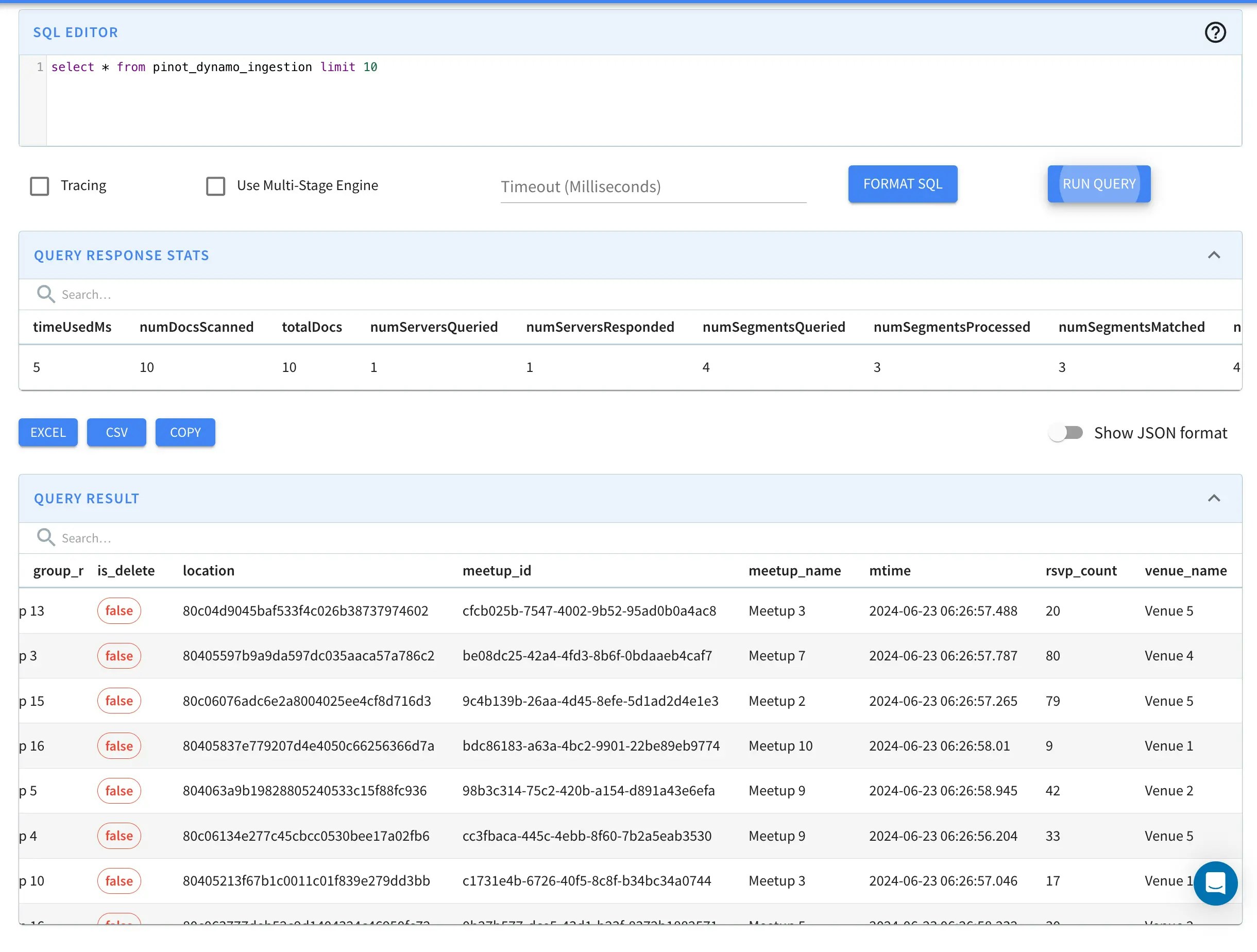
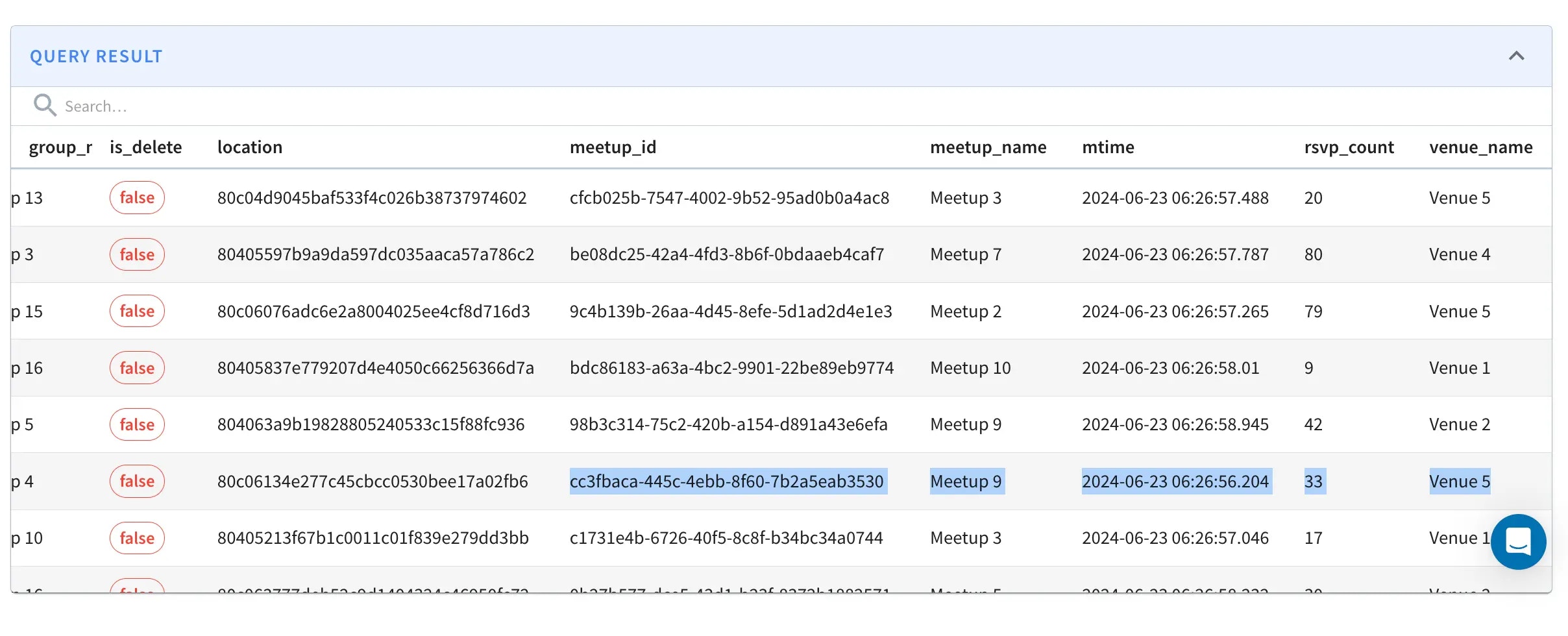
Update
Let’s update a row:Row before update
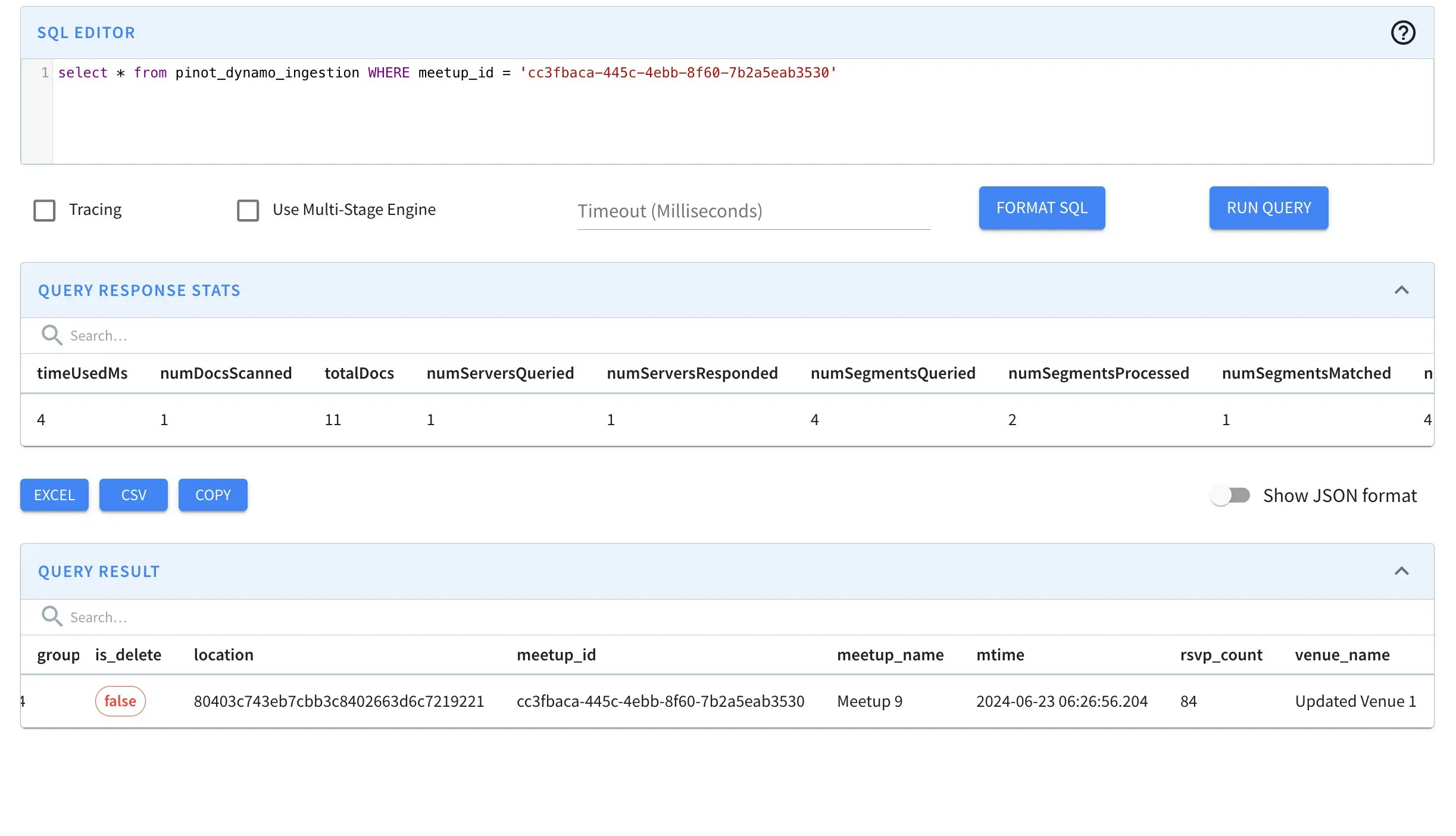
Row after update
Delete
To remove a row: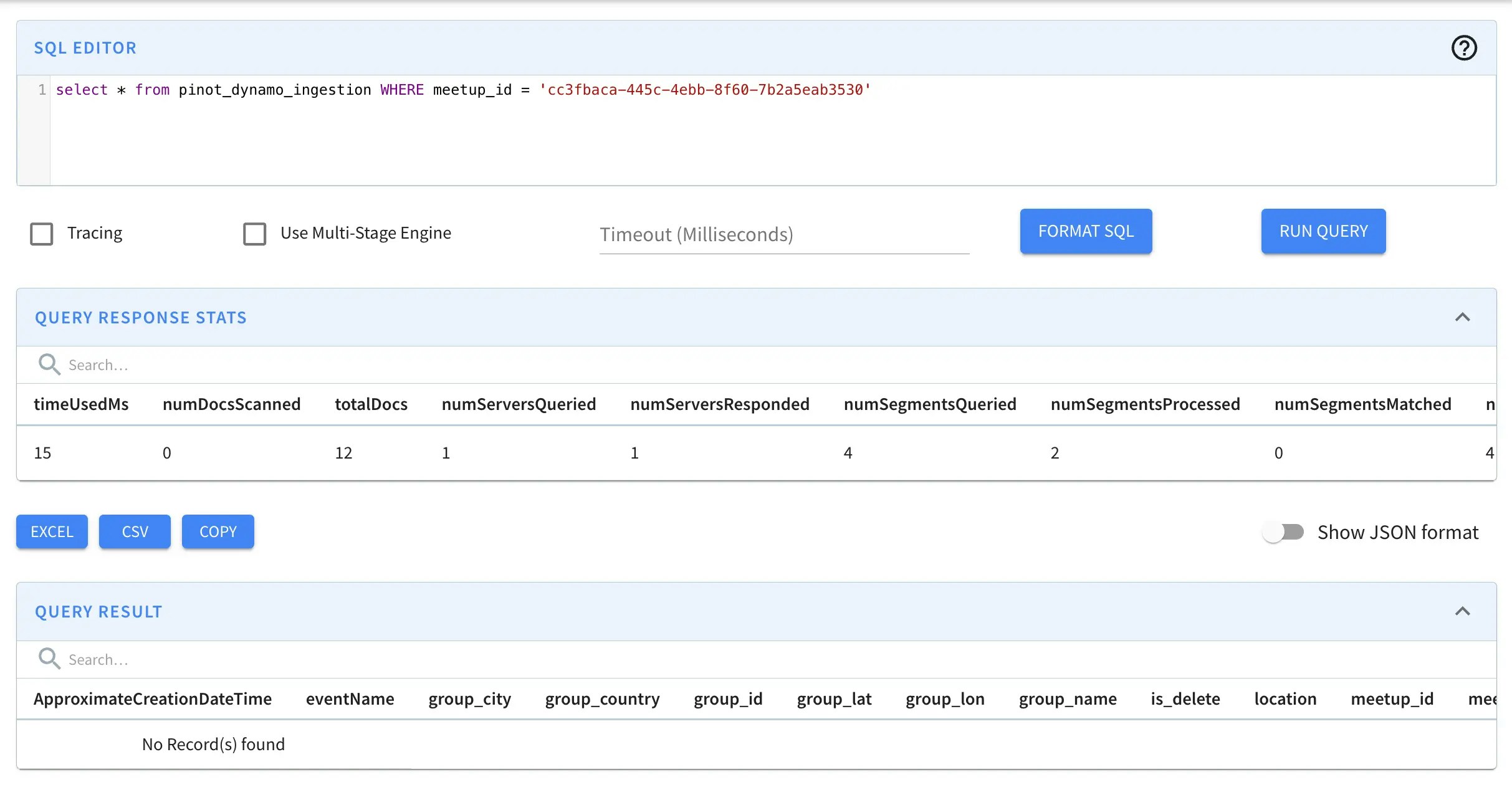
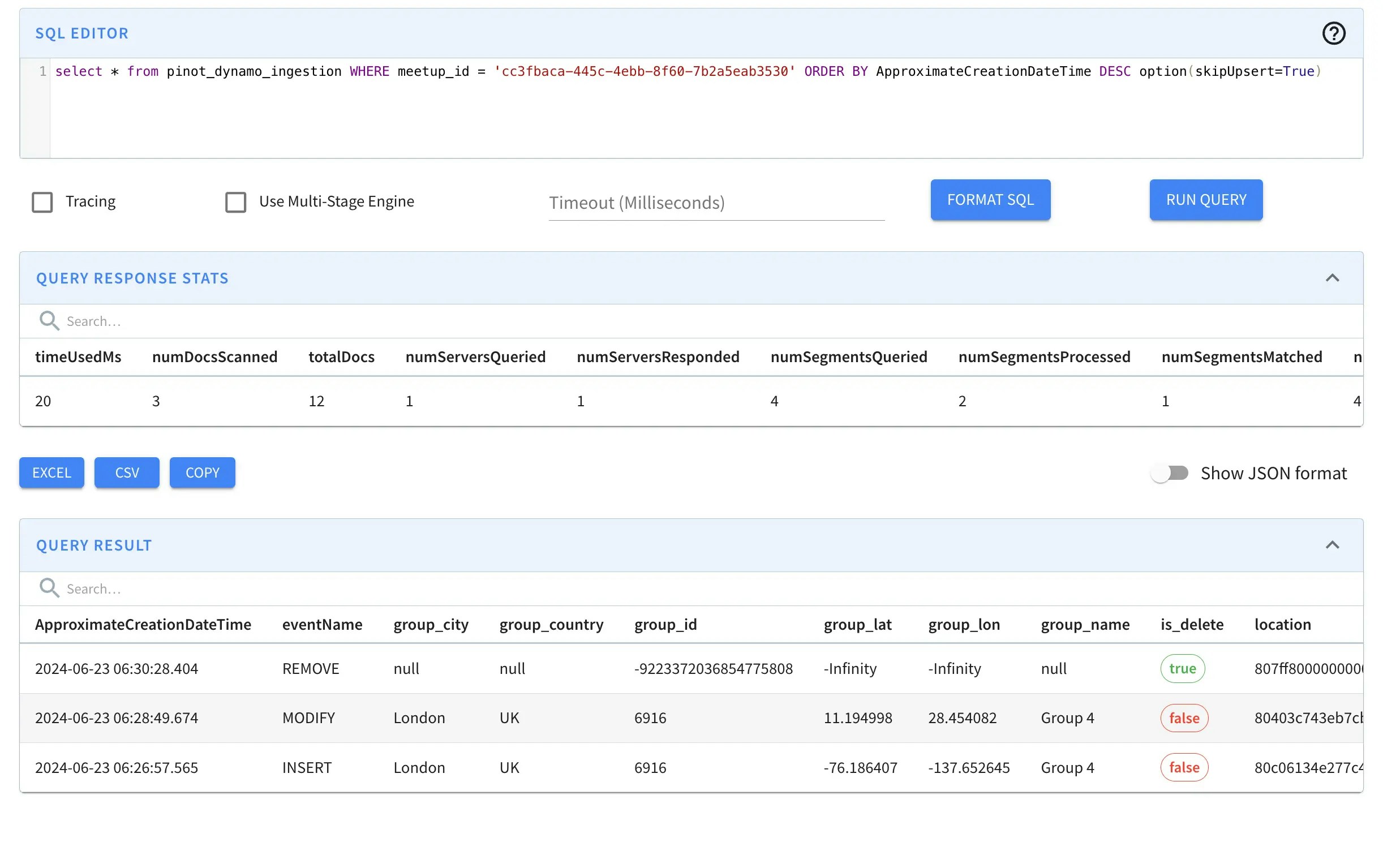
Behind the Scenes: Viewing Operation Order
Use the following in your Pinot queries: