> ## Documentation Index
> Fetch the complete documentation index at: https://docs.startree.ai/llms.txt
> Use this file to discover all available pages before exploring further.
> Learn about off-heap dedup and how to use them in StarTree
# Off-Heap Deduplication
Apache Pinot natively supports deduplication [dedup](https://docs.pinot.apache.org/basics/data-import/dedup) during real-time ingestion to handle scenarios where duplicate primary keys must be invalidated. Common use cases include invalidation of duplicate user logins (e.g., IP/UserID), prevention of duplicate orders in shipment tracking systems etc. Internally, Pinot servers keep track of dedup metadata to tell which segment holds it right now, so that the server drops duplicate records during ingestion. In the open-source implementation, dedup metadata is stored on-heap, leading to scalability issues when the data grows.
### Challenges with Open Source Dedup Implementation
1. Decline in query performance due to increasing memory overhead.
2. Ingestion delays caused by heap exhaustion and garbage collection.
3. Prolonged server restart times for large tables as metadata is rebuilt.
## StarTree’s Off-Heap Dedup
StarTree introduces off-heap deduplication using RocksDB to manage dedup metadata on disk. This approach reduces heap usage and improves scalability. Key functionalities include:
* **In-memory caching:** Recent reads are served from memory, minimizing disk access.
* **Batched writes:** Latest writes are buffered in memory and flushed to disk in large batches, reducing write latency.
* **Improved server restart times:** Metadata snapshots allow faster bootstrap of dedup tables reducing the preload time.
### Benefits of StarTree Off-Heap Dedup
1. Reduced JVM heap pressure, enabling better scalability for large tables.
2. Improved query latency by reducing contention on heap memory.
3. Minimized ingestion delays through efficient memory and disk usage.
4. Streamlined server restarts with prebuilt metadata snapshots.
## Configuration for Off-Heap Deduplication
Enable off-heap deduplication by setting the `enablePreload` and `metadataManagerClass` parameters in the dedupConfig. These parameters are enabled by default starting from January, 2025.
```json theme={null}
{
"dedupConfig": {
"dedupEnabled": true,
"hashFunction": "NONE",
"enablePreload": true,
"metadataManagerClass": "ai.startree.pinot.dedup.rocksdb.RocksDBTableDedupMetadataManager",
"metadataManagerConfigs": {
...
},
"dedupTimeColumn": "timeCol"
}
}
```
### Async Removal of Dedup Metadata
StarTree supports asynchronous removal of dedup metadata for deleted segments or expired keys based on Metadata TTL. This ensures consistent cleanup without impacting ingestion or query performance. The configs are enabled by default in StarTree, but one can change the cleanup frequency and key thresholds as shown:
```json theme={null}
{
"dedupConfig": {
"metadataManagerClass": "ai.startree.pinot.dedup.rocksdb.RocksDBTableDedupMetadataManager",
"metadataManagerConfigs": {
"rocksdb.asyncremoval.enable": "true",
"rocksdb.asyncremoval.threads": "1",
"rocksdb.asyncremoval.interval_in_seconds": 3600,
"rocksdb.asyncremoval.time_threshold_in_seconds": 86400,
"rocksdb.asyncremoval.key_threshold": 1000000
}
}
}
```
## Metadata TTL
With `metadataTTL` in [Open Source Pinot](https://docs.pinot.apache.org/basics/data-import/dedup#metadata-ttl), metadata is removed when next consuming segment starts which can be minutes or even hours, depending on the segment commit frequency. At StarTree, the dedup metadata is cleaned up by the async removal process as mentioned above. This is particularly useful for scenarios where duplicates are unlikely after a certain time.
```json theme={null}
{
"dedupConfig": {
"metadataTTL": 86400
}
}
```
### RocksDB Customization
When using the off-heap dedup, the server creates one RocksDB store to be shared by all the dedup tables for better efficiency. RocksDB stores data in SST (Sorted String Table) files on disk. There are some configurations which can be useful like configuring buffer size at db level and at columnfamily level. DB-level buffer size: Maximum size of all memtables combined across column families (default: 5GB). ColumnFamily buffer size: Maximum size of each memtable before being flushed to disk (default: 100MB).
### Default cluster settings:
```json theme={null}
{
"pinot.server.kvStoreFactory.class.rocksdb": "ai.startree.pinot.common.rocksdb.metastore.RocksDBStore",
"pinot.server.kvStoreFactory.rocksdb.datadir": "/home/pinot/data/index/metadata/common",
"pinot.server.kvStoreFactory.rocksdb.common.delete.on.exit": "true",
"pinot.server.kvStoreFactory.rocksdb.db.db.write.buffer.size": "5368709120",
"pinot.server.kvStoreFactory.rocksdb.columnfamily.write.buffer.size": "104857600"
...
}
```
Each table partition creates its own `ColumnFamily` in the shared RocksDB store. To customize the table's `ColumnFamily` add the following RocksDB configs in the `metadataManagerConfigs` section. The config names are kept consistent with [those available for RocksDB](https://betterprogramming.pub/navigating-the-minefield-of-rocksdb-configuration-options-246af1e1d3f9).
```json theme={null}
"dedupConfig" : {
"enablePreload": true,
"metadataManagerClass": "ai.startree.pinot.dedup.rocksdb.RocksDBTableDedupMetadataManager",
"metadataManagerConfigs": {
"rocksdb.blockcache.size_bytes": "1073741824",
"rocksdb.rowcache.size_bytes": "104857600"
...
}
}
```
## Dedup Snapshot Creation
For large tables with millions or billions of primary keys, server restart times can be significantly reduced using prebuilt dedup metadata snapshots during preload. These snapshots are created by minion using the `DedupSnapshotCreationTask`, and persisted in deep store, later imported by servers during restart. This mechanism minimizes restart delays by eliminating the need to rebuild metadata using read and write for each record.
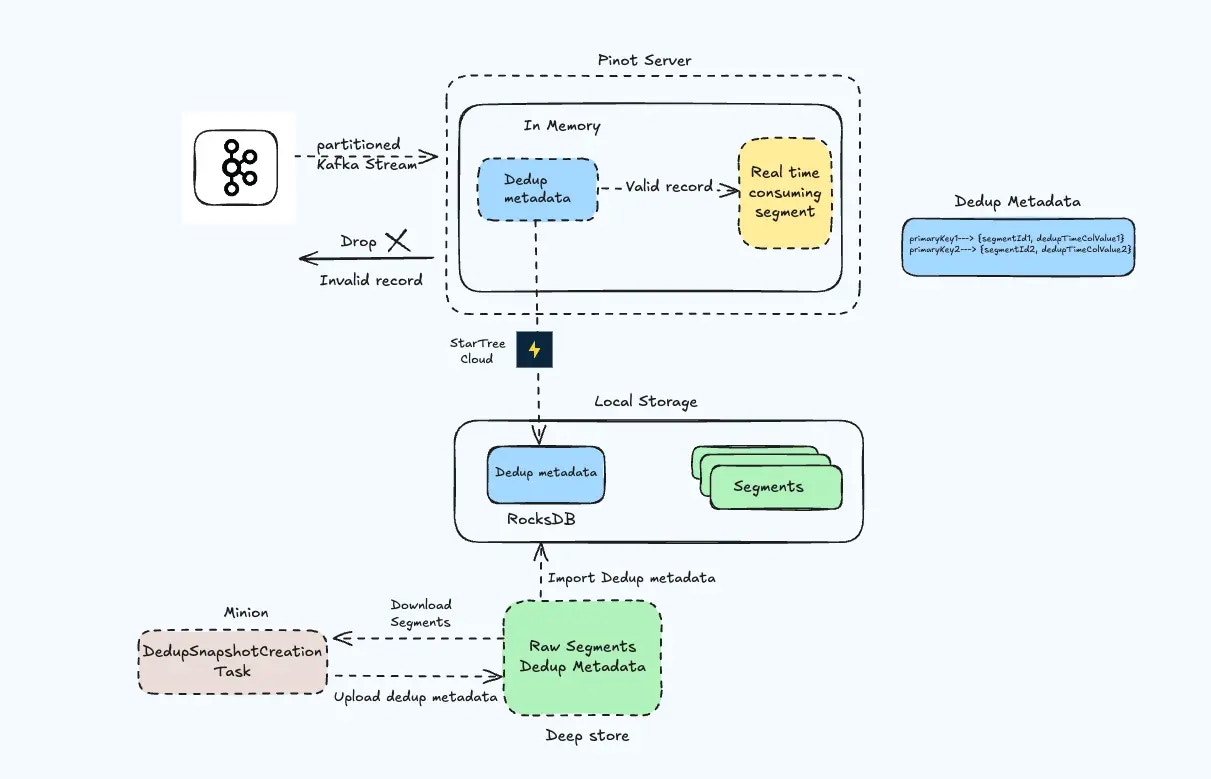 This minion task runs periodically to keep updating the prebuilt dedup metadata incrementally. To enable the minion task, add the following task configs. See [the Pinot docs](https://docs.pinot.apache.org/basics/concepts/components/cluster/minion) to understand how to schedule a minion task.
```json theme={null}
"task": {
"taskTypeConfigsMap": {
"DedupSnapshotCreationTask": {
"schedule": "0 0 12 * * ?"
}
}
}
```
### Partition Configuration
The `DedupSnapshotCreationTask` requires partition information to schedule tasks effectively. If the table has`segmentPartitionConfig` with a single partition column, the task uses the `numPartitions` field:
```json theme={null}
"tableIndexConfig": {
"segmentPartitionConfig": {
"columnPartitionMap": {
"": {
"numPartitions": ,
...
}
}
}
}
```
For tables with multiple partition columns or missing `segmentPartitionConfig`, explicitly specify the partitions:
```json theme={null}
"dedupConfig": {
...
"metadataManagerConfigs": {
"rocksdb.preload.num_partition_overwrite": ""
}
}
```
As tasks complete, following Restful APIs can be used to inspect the prebuilt dedup metadata.
```
/dedupSnapshots/{tableNameWithType}/names
/dedupSnapshots/{tableNameWithType}/{snapshotName}/metadata
/dedupSnapshots/{tableNameWithType}/latest
```
Note that using the health check `PREBUILT_SNAPSHOT_CHECK`, we can identify those dedup tables whose snapshot generation task is disabled in a cluster.
## Segment Operation Throttling
When segments are added to a server, it undergoes various operations to come online and be ready for query processing. One of these expensive operations is related to updating the RocksDB state for dedup tables if snapshots are not available. Throttling has been added to limit the number of segments that can undergo this operation to limit the resource utilization usage during this operation. The following configs have been added to control the throttle threshold:
* Before serving queries config: `pinot.server.max.segment.rocksdb.parallelism.before.serving.queries`
* After serving queries config: `pinot.server.max.segment.rocksdb.parallelism`
More about segment operations throttling and how to make changes can be found in [the Pinot docs](https://docs.pinot.apache.org/operators/tutorials/segment-operations-throttling).
## Ingestion Pause on too many Primary Keys per Server
When the number of primary keys per server gets too large, this can result in various issues:
* RocksDB latency increase on query and ingestion path
* Server restarts and rebalance scenarios can become slow even when snapshots exist
To prevent the system from getting into the above state, we will now pause ingestion for dedup tables when a threshold is reached on any server for that table. The configs of interest:
* The primary key count threshold (defaults to 3 billion): `controller.primary.key.count.threshold`
* The primary key count check timeout (defaults to 30 seconds): `controller.primary.key.count.check.timeoutMs`
Other related configs common with the DiskUtilization check mechanism (which also pauses ingestion) are:
* Flag to enable / disable the resource utilization check: `controller.enable.resource.utilization.check`
* Resource utilization check frequency: `controller.resource.utilization.checker.frequency`
* Initial delay to start the resource utilization check: `controller.resource.utilization.checker.initial.delay`
## Frequently Asked Questions
Enabling `dedupConfig` on existing real time tables is not advised and it will not eliminate any duplicate records from the existing segments, but newly ingested data will start to get deduplicated after enabling dedup. If the user still wishes to enable it on the existing table, add the `dedupConfig` and restart the server, beware they may see duplicates in existing segments until the segments get deleted from the table, for example due to data retention.
It is possible to convert an upsert table to dedup table but it's recommended to run compaction task [upsert compaction](https://docs.pinot.apache.org/manage-data/data-import/upsert-and-dedup/segment-compaction-on-upserts) to remove invalid docs from existing segments first, so that those invalid docs won't become duplicates when enabling dedup. A server restart is needed to convert an upsert table to a dedup table.
Currently, enabling both upsert and dedup on one table is not supported.
Note that the upstream data needs to be partitioned correctly, and a primary key should not exist in different partitions as it will be served by different servers. Make sure `metadataTTL` in `dedupConfig` is set to an approipriate value and duplicate primary keys are not ingested beyond this ttl window.
This minion task runs periodically to keep updating the prebuilt dedup metadata incrementally. To enable the minion task, add the following task configs. See [the Pinot docs](https://docs.pinot.apache.org/basics/concepts/components/cluster/minion) to understand how to schedule a minion task.
```json theme={null}
"task": {
"taskTypeConfigsMap": {
"DedupSnapshotCreationTask": {
"schedule": "0 0 12 * * ?"
}
}
}
```
### Partition Configuration
The `DedupSnapshotCreationTask` requires partition information to schedule tasks effectively. If the table has`segmentPartitionConfig` with a single partition column, the task uses the `numPartitions` field:
```json theme={null}
"tableIndexConfig": {
"segmentPartitionConfig": {
"columnPartitionMap": {
"": {
"numPartitions": ,
...
}
}
}
}
```
For tables with multiple partition columns or missing `segmentPartitionConfig`, explicitly specify the partitions:
```json theme={null}
"dedupConfig": {
...
"metadataManagerConfigs": {
"rocksdb.preload.num_partition_overwrite": ""
}
}
```
As tasks complete, following Restful APIs can be used to inspect the prebuilt dedup metadata.
```
/dedupSnapshots/{tableNameWithType}/names
/dedupSnapshots/{tableNameWithType}/{snapshotName}/metadata
/dedupSnapshots/{tableNameWithType}/latest
```
Note that using the health check `PREBUILT_SNAPSHOT_CHECK`, we can identify those dedup tables whose snapshot generation task is disabled in a cluster.
## Segment Operation Throttling
When segments are added to a server, it undergoes various operations to come online and be ready for query processing. One of these expensive operations is related to updating the RocksDB state for dedup tables if snapshots are not available. Throttling has been added to limit the number of segments that can undergo this operation to limit the resource utilization usage during this operation. The following configs have been added to control the throttle threshold:
* Before serving queries config: `pinot.server.max.segment.rocksdb.parallelism.before.serving.queries`
* After serving queries config: `pinot.server.max.segment.rocksdb.parallelism`
More about segment operations throttling and how to make changes can be found in [the Pinot docs](https://docs.pinot.apache.org/operators/tutorials/segment-operations-throttling).
## Ingestion Pause on too many Primary Keys per Server
When the number of primary keys per server gets too large, this can result in various issues:
* RocksDB latency increase on query and ingestion path
* Server restarts and rebalance scenarios can become slow even when snapshots exist
To prevent the system from getting into the above state, we will now pause ingestion for dedup tables when a threshold is reached on any server for that table. The configs of interest:
* The primary key count threshold (defaults to 3 billion): `controller.primary.key.count.threshold`
* The primary key count check timeout (defaults to 30 seconds): `controller.primary.key.count.check.timeoutMs`
Other related configs common with the DiskUtilization check mechanism (which also pauses ingestion) are:
* Flag to enable / disable the resource utilization check: `controller.enable.resource.utilization.check`
* Resource utilization check frequency: `controller.resource.utilization.checker.frequency`
* Initial delay to start the resource utilization check: `controller.resource.utilization.checker.initial.delay`
## Frequently Asked Questions
Enabling `dedupConfig` on existing real time tables is not advised and it will not eliminate any duplicate records from the existing segments, but newly ingested data will start to get deduplicated after enabling dedup. If the user still wishes to enable it on the existing table, add the `dedupConfig` and restart the server, beware they may see duplicates in existing segments until the segments get deleted from the table, for example due to data retention.
It is possible to convert an upsert table to dedup table but it's recommended to run compaction task [upsert compaction](https://docs.pinot.apache.org/manage-data/data-import/upsert-and-dedup/segment-compaction-on-upserts) to remove invalid docs from existing segments first, so that those invalid docs won't become duplicates when enabling dedup. A server restart is needed to convert an upsert table to a dedup table.
Currently, enabling both upsert and dedup on one table is not supported.
Note that the upstream data needs to be partitioned correctly, and a primary key should not exist in different partitions as it will be served by different servers. Make sure `metadataTTL` in `dedupConfig` is set to an approipriate value and duplicate primary keys are not ingested beyond this ttl window.